The Battle of the Neighbourhoods
IBM: Applied Data Science Capstone
14/01/2021
Introduction
A venture capitalist is known as a private equity investor who seeks opportunity in high-growth potential companies such as small businesses and startups in exchange for a stake in the respective company. The risk-reward factor of investing in these companies can be drastic, and if invested correctly can yield a substantial return for the investor. Venture capital firms began in the United States in the early to mid-1900s and has continued to grow exponentially as the world evolved through the Dot-Com burst and into the Fourth Industrial Revolution1.
The popular television show Shark Tank and its respective spinoff such as Dragon's Den in the UK has brought to life the way investors, specifically venture capitalists invest their money in small businesses and startups. In order to mitigate the risks, investors must know about the business and what the plan would be to succeed.
This project aims to provide information to venture capitalists on what businesses are popular based on data about Toronto, Canada. The idea is to be able to make valid assumptions based on the popularity of certain venues in the various boroughs. The information gathered will allow venture capitalists to know what type of businesses are in high-demand as well as potential opportunities for less popular businesses.
Data
Based on what we aim to achieve with this project, the data required includes:- List of postal codes, corresponding boroughs and neighbourhoods for the City of Toronto.
- The demographics of the Toronto neighbourhoods.
- The various venues such as restaurants, bars, coffee shops, malls, etc. around each of the neighbourhoods.
- The longitude and latitude of each neighbourhood and venues.
Data Sources
The list of postal codes, boroughs and neighbourhoods are retrieved from a Wikipedia table listing all of the postal codes in Canada that begin with the letter M. This was chosen as the postal codes that begin with the letter M are the boroughs and neighbourhoods that are found within the city of Toronto. The original table is found at the link below:
https://en.wikipedia.org/wiki/List_of_postal_codes_of_Canada:_M
This postal code data along with the corresponding boroughs and neighbourhoods will correlate directly with the geospatial data file. This data file provides the longitude and latitude of each postal code that is stored in a csv file. The link to the file can be found at the link below:
http://cocl.us/Geospatial_data
The demographics data is taken from the Toronto Open Data Catalogue, relating to neighbourhood profiles. The csv file consists of the neighbourhood profiles from a census done in 2016, which includes population distribution across various races and religions, languages spoken, immigration and citizenship, education and finances. This file is provided as a csv file and can be found at the link below:
These above links alongside the Foursquare API will be used to map the neighbourhoods and retrieve the data relating to the various venues. For this project, due to the limitations of the free account on Foursquare, the search limit of the venues is set to 100 with a radius of 500 metres of each neighbourhood.
Methodology
Importing the Libraries
Various libraries will be used through the implementation of this project, with the main ones being
pandas and numpy to handle the data itself. The geopy,
folium and
requests libraries will handle longitude and latitude conversion, JSON handling and map
rendering
respectively. The Sci-kit learn library gives us access to the k-means clustering model
for our
project execution and analysis. Lastly, the BeautifulSoup library will extract data
from the
respective HTML pages and allow us to use that data in a dataframe for analysis and modelling.
Importing the Data Sources
Toronto Neighbourhoods Data
In order to obtain this data from the Wikipedia page, theget function is used to request
the
page and convert it to raw HTML text. Using the BeautifulSoup library the table can be
identified
and converted into raw HTML text. Following this, the table is then read as an HTML file and converted
into a dataframe for processing. Figure 1 shows the original Wikipedia table whereas
Figure 2 shows the same data after being converted to a dataframe.

Preprocessing the Neighbourhoods Data
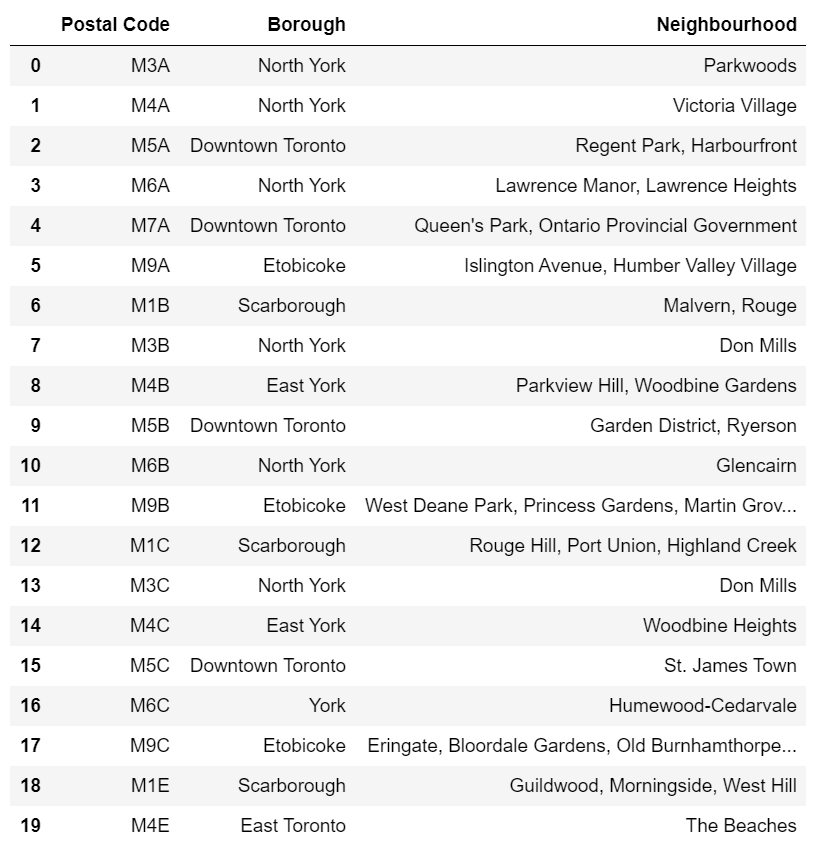
With the data having been imported correctly, it now must be preprocessed before any modelling and analysis can be done. The first step is to drop all rows from the table where the boroughs are Not assigned. The next step is to assign all Not assigned neighbourhoods the value of their respective boroughs. Figure 3 shows the table after being preprocessed and ready for assigning the respective longitude and latitude values to each location.
Geospatial Data
The Geospatial data is the data that will provide the geographical coordinates to the neighbourhoods, specifically the centre point of each neighbourhood. The data is stores in a csv file, and is read in as such and converted into a dataframe. Subsequently, this data must be merged with the neighbourhoods dataframe for the data to be modelled and analysed. A left join is done on the neighbourhoods table with the geospatial data table and the resulting dataframe can be seen in Figure 4.

Demographics data (used for in-depth analysis
The demographics data is a csv file that was extracted from the Toronto open Data Catalogue and contained data from a 2016 census. With the amount of information in this file only two rows were extracted, specifically the population of the neighbourhoods and the average income of the neighbourhoods. This data was read in, preprocessed and merged with the Neighbourhoods dataframe. The resulting table can be seen in Figure 5.

Creating the Map
In order to generate an interactive map with points over each neighbourhood, the folium
and
geopy libraries are used. The geopy retrieved the centre coordinates of
the city of
Toronto, and the folium library is able to take the data from the dataframe as well as
the
location of Toronto and map it out accordingly as seen in Figure 6.
Retrieving the venue
With half of the data ready for modelling and analysis, we can now extract the data required from the Foursquare API. The initial step is to set up your Foursquare credentials in order to retrieve the requested information. Once authenticated, 100 venues within a 500 metre radius of each neighbourhood. This data is requested as a JSON file and once received is converted into a dataframe which can be seen in Figure 7.
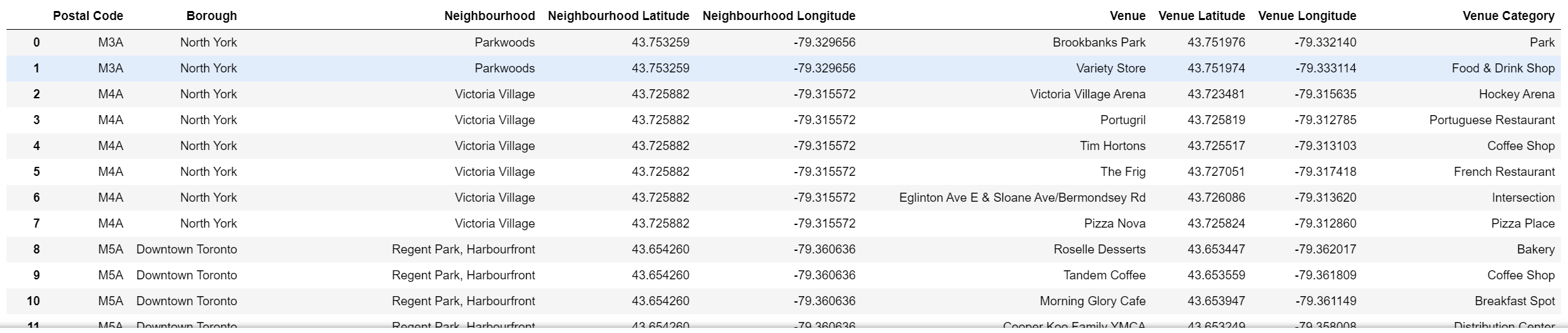
Grouping the Venues
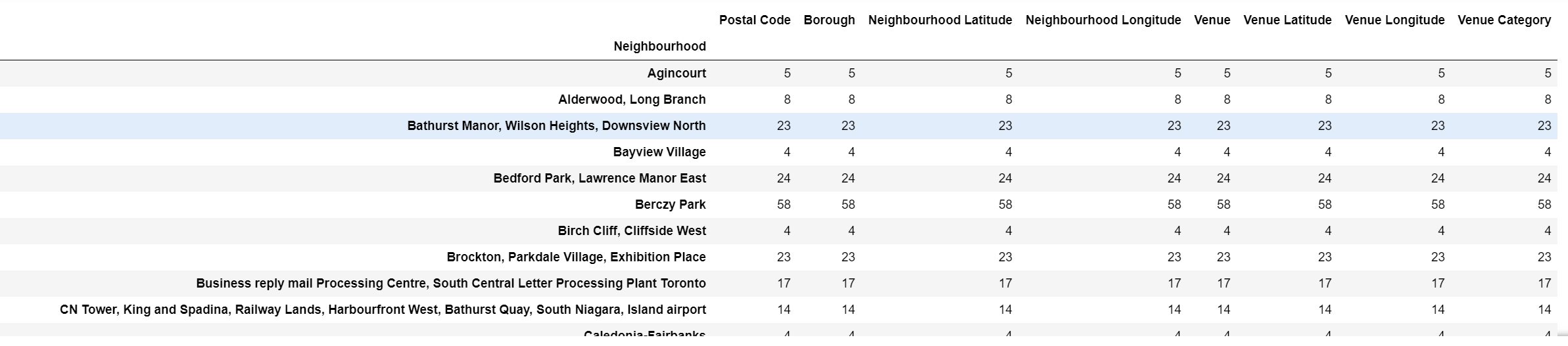
All the venues within the requested radius has been presented, however in order to gain a full understanding of the data, the venues are grouped and counted. This is to observe what are some of the popular venues within the city of Toronto. The results can be seen in Figure 8 which amounts to a total of 273 unique categories of venues. Since no dictionary or classification is done on the venue categories, a café and a coffee shop and a breakfast place are all categorised as unique venues, which for this project was an accepted trade off.
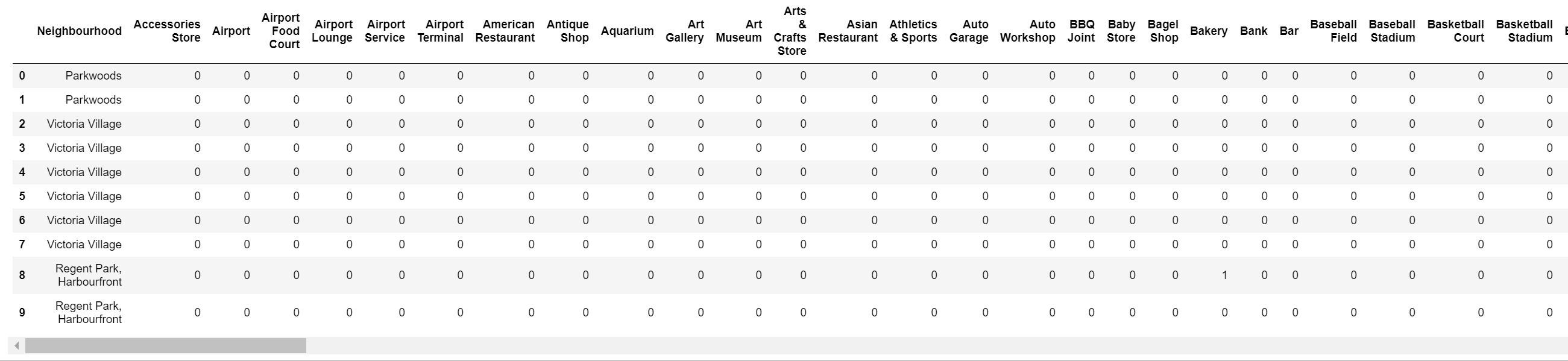
One Hot Encoding
One Hot Encoding is a process where categorical variables can be converted in order for a machine
learning algorithm to process the data2. This converts the variables
into a binary format,
where a 0 indicates no occurrence and a 1 indicates an occurrence of that respective variable.
Figure 9 shows the venues dataframe after being passed through the onehot
function.
Calculating the average occurrence of each venues
Once processed and done, One Hot Encoding simply states if that categorical variable, in this case a venue, is present in that neighbourhoods radius. It does not give an indication of how many times that specific venue occurs in the radius. In order to achieve this, the neighbourhoods are grouped and the means of each venue is calculated as seen in Figure 10.

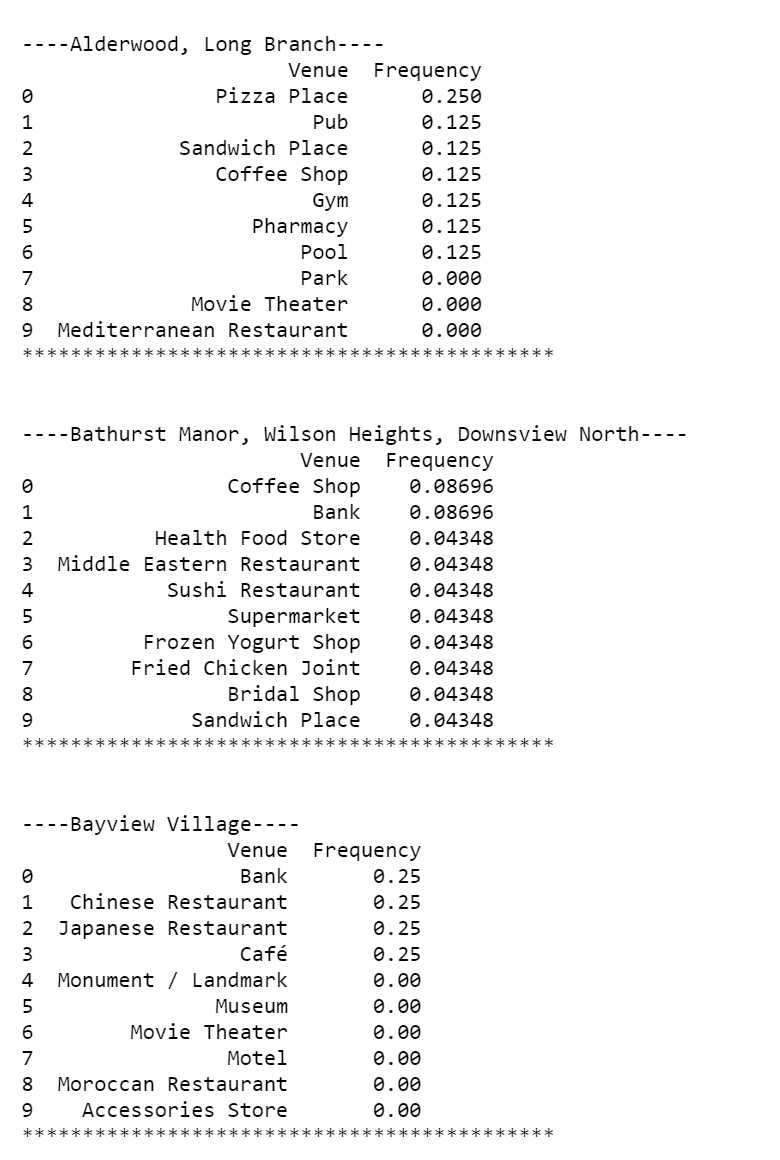
Presenting the top 10 venues of each neighbourhood
Now that the means are calculated for each venue for each neighbourhood,the goal is to retrieve the top 10 venues in each neighbourhood to allow investors to see what is the most popular venue categories and what would pose the most competition. Figure 11 displays an example of the top 10 venues of three different neighbourhoods. This raw text data can now be converted into a dataframe for clustering, which can be seen in Figure 12.

Clustering
The clustering used in this project is the k-means clustering. Five clusters were chosen for the categorisation in order to prevent underfitting and overfitting of the data given the concentration of the various neighbourhoods in the city of Toronto. Figure 13 shows the final processed dataframe after being passed through the machine learning algorithm.

Results
Cluster Map
The neighbourhoods are all clustered, and in order to gain a better understanding on how they were clustered, a map is generated with each cluster being presented in a different colour. Figure 14 displays the map, where the following clusters correspond to the following clusters: gray is cluster 1; black is cluster 2; red is cluster 3; blue is cluster 4; purple is cluster 5.
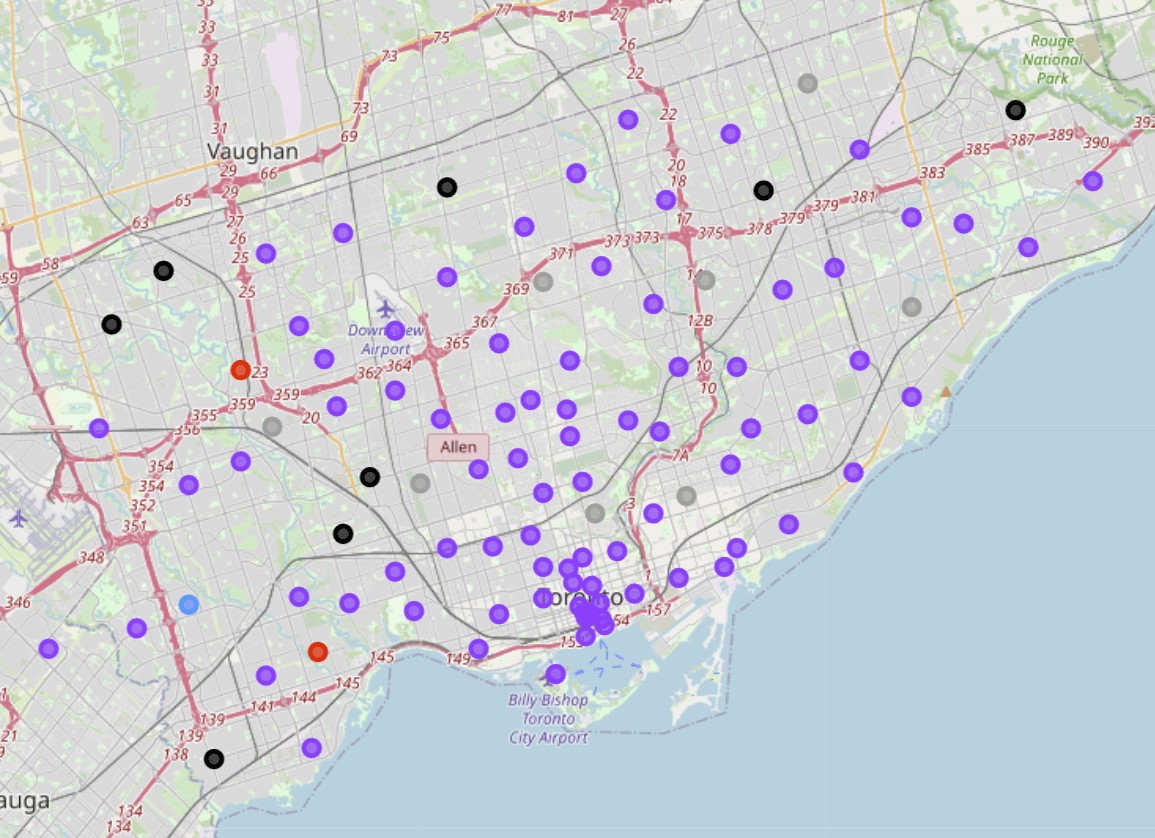
Cluster 1
If we analyse cluster 1, we can see that based on the most popular venue across all the neighbourhoods are parks and playgrounds. Across the top 10, it seems that all of these neighbourhoods have similarities as the rank of the venues decrease, for example the fifth to the 8th most common venues for the first four neighbourhoods have Dog run, Doner Restaurant, Donut shop and Drugstore in the same order.
.
Cluster 2
Cluster 2 has a Pizza place as it's most common venue in the various neighbourhoods. The various types of restaurants are spread across the rank of each neighbourhood, however almost all exist in each other, albeit at a lower or higher rank. An example of this would be the Eastern European restaurant being the third most common venue for the first two neighbourhoods, but the fifth most common venue for the fourth neighbourhood.

Cluster 3
Cluster 3 may not seem to have any similarities with regards to their venues, however these two neighbourhoods are clustered together due to the similarities of their location. Although not regarded as a venue, these two neighbourhoods are situated next to middle schools.

Cluster 4
Cluster 4 is somewhat of an outlier as no other neighbourhoods are similar to this, as it's most common venue is a Filipino restaurant. As no other cluster has this in common, this neighbourhood is clustered by itself.

Cluster 5
Cluster 5 has the most neighbourhoods in it and shows blatant similarities in the most common venues. These neighbourhoods are clustered together as they are all high-density residential areas.

Discussion & In-Depth Analysis
For the in-depth analysis, 10 neighbourhoods were chosen and their respective populations and average income was extracted and combined into a single dataframe. These 10 cities will stand as an example to what can be done with this type of clustering and analysis. Figure 20 shows the dataframe of the 10 neighbourhoods while Figure 21 presents the previously clustered neighbourhoods and corresponding clusters.
The main analysis would rather happen from the dataframe as the pertinent data is presented. If we take the second neighbourhood, Humewood-Cedervale, for example we can analyse the following:
- The neighbourhood is in the fifth cluster, meaning it is in a residential area.
- The top five most common venues are all healthy or sport related venues.
- There is no healthy restaurant or healthy food store in the top 10 most common venues.
- Given the smaller population size, but with the second highest average income in this list, it could stand that a venture capitalist may see an opportunity to invest in a healthy food store that already exists in the area to begin a small franchise.
- Increasing the number of same-branded healthy food stores can result in more people having access to the stores and make it potentially the sixth most common, if not one of the top five most common venues in the neighbourhood.
Conclusion
A project was implemented on analysing data of the city of Toronto relating to its neighbourhoods. The data was sourced from various locations, preprocessed and presented accordingly. The data was then modelled and clustered using the k-means clustering machine learning algorithm, and an analysis was done on the results. An in-depth analysis was done given more information such as population and average income of the neighbourhood to answer the problem posed in this project. Overall, the project was successful but can stand to be improved with recommendations being given.References
1
Ganti, A; Venture Capitalist (VC) Definition;Last Accessed:
15/01/2021
2
Vasudev, R; What is One Hot Encoding? Why and When Do You Have to Use it?; Last Accessed:
15/01/2021